Research
The prominent theme covered in my research is language change, especially the relationship between change on the one hand, and social identity and multilingual language practice on the other. My research has progressed from a strictly diachronic perspective to include aspects of synchronic variationist linguistics, and more recently second language acquisition and psycholinguistic perspectives on multilingualism. Nevertheless, the underlying questions in my research remain diachronically oriented. Throughout my studies and career as a linguist, I have been engaged with inter- and multidisciplinary approaches to the study of language, relying on data-driven and usage-based accounts of language as a basis for both research and teaching.
Current Research
New Speakers of Minority Languages: ...
2021-2023
Short Title | Acronym: NESPOMILA
Following my posdoctoral project, which investigated the relationship between language variation and change among new speakers of Wymysorys, I aim to apply the methodological approach to the case of other minority languages.
Endangered minority languages in Europe have seen an upsurge in revitalization activities in recent decades. The most successful of these are organized at the grassroots level and consist of out-of-home language learning programs, which initiate new speakers in an effort to increase the overall speaker population of that language. As typically very active members within an endangered language speech community, those engaged with revitalization activities, who are often new speakers themselves, are in a prime position to influence community wide speech behavior, reestablishing norms set by previous generations of speakers. Because these new speakers are learners themselves and situated within the already volatile linguistic setting due endangerment, they provide an ideal case to study the relationships among language acquisition, language variation, and language change.
In the summer of 2019, I ran a brief pilot, collecting data among young(er) Kashubian speakers. In the current (2021–2023) project New speakers of minority languages: Proficiency, variation, and change, we continue looking at developments in Wymysorys, and expand the pool of case studies with Kashubian and control groups consisting of learners of non endangered|minoritized languages. Unfortunately, COVID-19 threw us a gnarly curve ball in terms of our ability to safely and ethically conduct field research, so I've been busy developing software to collect spoken language data remotely. More info can be found on the project website.
NCN under POLS instrument, contract 2020/37/K/HS2/02779.
* * *
Automating Spoken Language Corpora
2019–ongoing
If you have ever had the "pleasure" of transcribing audio recordings of spoken language, you'll know that it is a time consuming, tedious, and potentially frustrating endeavor. As a linguist with a usage-based theoretical orientation, my work is based on actual observations of empirical, spoken language data. However, the majority of tools and techniques developed in corpus linguistics that are capable of aiding analyses of relatively large sets of data rely on textual data. The investment required to transcribe audio, largely limits the size of spoken language corpora, meaning that studies of spoken language tend to rely on relatively small, expensive-to-create corpora. This bottleneck problem problem is potentially solved — at least for some languages — with the help of speech recognition. I have developed a set of workflows that utilizes speech recognition technology to "auto-transcribe" spoken data from languages where recognition technology is already available. The workflow combines the power of shell scripting and Python with the utility of ELAN and its XML-based data storage in order to chunk and speech recognize audio, then time-align the output text with the original audio. This "set it and forget it" method allows for the relatively fast creation of textual corpora from spoken language data, making these data available to the tools and techniques used in corpus linguistics. I'm currently working on two case studies that employ this workflow.
In one case, we (van den Berg and I) worked on data processed in this way from the Surinamese Parliament — De Nationale Assemblée. We took a descriptive, variationist approach to the data, looking at features that have been described in other publications as distinctive in the Surinamese variety of Dutch. The results of our investigation show that a data heavy approach, such as the one we have taken, will lead to a more nuanced understanding of how particular features and their distribution signal "Surinameseness". Find our presentation from SPCL 2019 summer meeting in Lisbon here. A full paper version will be published soon.
In a more recent rendition, Volker Gast and I have been working on data from the European Parliament. So far, I have mainly been dealing with infrastructural issues. In the Europarl case, video files come with multiple embedded audio tracks; every bit of spoken language is translated simultaneously to all the other EU languages and these translations are embedded to the video file. Currently, the pipe extracts all these audio tracks and builds the Elan readable .eaf file with a transcription for each language track.
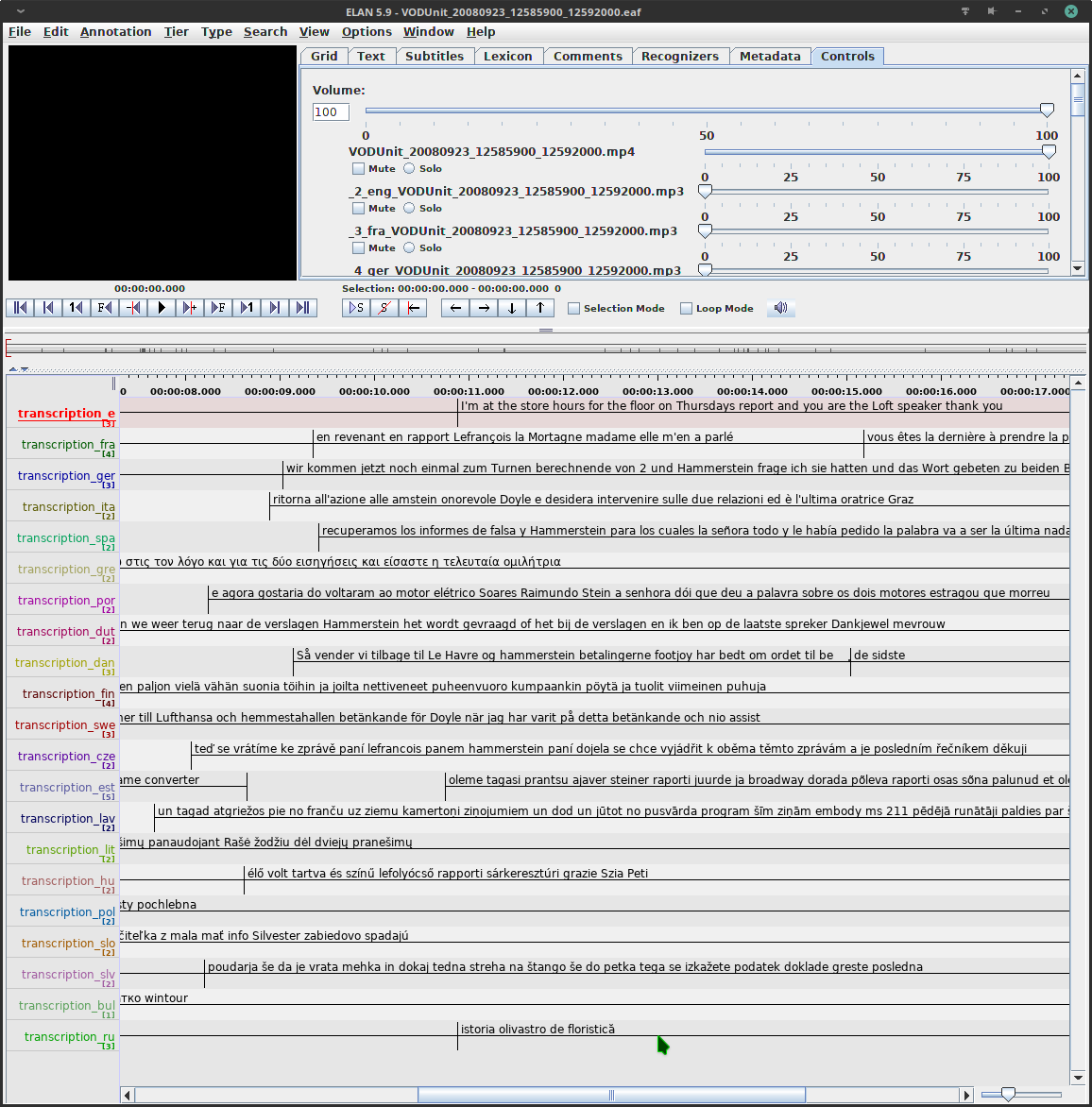 Screenshot of transcriptions resulting from the speech-to-text pipe as seen in Elan
Screenshot of transcriptions resulting from the speech-to-text pipe as seen in Elan
We're still exploring possibilities for exactly how we will proceed with analysis of data, but we see enormous potential to address questions related to the translation studies and the multilingual mind.
* * *
Past Research Project
New Speakers of Wymysorys: the reconstitution of the local language and sociolinguistic identity in Wilamowice
2017–2019
The project New Speakers of Wymysorys: the reconstitution of the local language and sociolinguistic identity in Wilamowice operates under the main hypothesis that "new speakers" provide an ideal context to observe the instantiation of linguistic innovation and the spread of these innovations within a speech community in situ. In brief, a new speaker here refers to an individual who has learned a language with little or no exposure in the home via educational programs outside the home after a community-level shift (Orourke, Pujolar, and Ramallo 2015:1). Situated in already volatile speech communities thanks to language shift, new speakers tend to play an active role in the community and represent larger and more influential proportion of the overall speech community than learners of non-threatened languages. Such contexts are conducive to the observation of the development interlanguage features that spread through dense networks of minority language users and ascend to the status of or model for other language learners, replacing the ``native'' variety as target.
As a critically endangered language, Wymysorys serves as an ideal case in the study of new speakers. Wymysorys is a West Germanic language, spoken in the southern part of Poland, at the boarder of the Silesian and Lesser Poland Voivodships. The language became threatened due to severe oppression by communist authorities after WWII; speakers were required to hide their affiliation with the language for survival. Today there are approximately fifty speakers of the language; about half of them are elderly (>80) "native speakers" and the rest are teenagers and twenty-something new speakers, who learned the language through grassroots revitalization efforts that began ca. ten years ago, led almost exclusively by children.
In order to observe change, a relatively data-heavy approach is necessary, thus a longitudinal design has been implemented whereby a similar set of tasks are used to collect data from the same individuals at different points in time. The data collection procedures rely on best practices set out in Language Documentation and draw on methods developed in sociolinguistics and psycholinguistics. In a nutshell, participants:
- answer a set of closed questions (questionnaire)
- narrate a short series of video clips
- complete a rapid automated picture naming (RAN) test in Wymysorys and Polish
- answer a set of open-ended questions (interview)
- complete a series of director-matcher tasks (in pairs)
These procedures result in a rich set of data for each speaker at a given time, including spoken language data, experimental data, and information about the speaker's background, language attitudes, experiences as a new speaker, language practices, and social networks.
Data are then subject to a mixed methods analysis to elucidate individual and group trajectories. Questionnaires result in a set of numerical answers, which are used as a basis for constructing speaker profiles, and are stored for further quantitative analysis as variables in conjunction with language data. Spoken language data (narration and director-matcher task) are transcribed in functional orthography and analyzed in terms of morphosyntactic feature variation. Proficiency measures are also derived directly from the spoken language data, including words per minute, "um" rate, and lexical density. The experimental data derived from the RAN test is analyzed in terms of naming latencies in order to derive a measure of entrenchment for Wymysorys and Polish in each speaker. Interview data are analyzed in terms of Interpretational Phenomenological Analysis (Smith 1996) in order to better understand how speakers construct their own experiences within the prevalent societal ideologies. Finally, with these ``snap shots'' of each speaker individual trajectories of acquisition, group development, and the spread of linguistic innovation can be constructed.
The project was carried out with the support of Uppsala University as part of a multidisciplinary postdoctoral carried out at Hugo Valentin Centre.
* * *
Nahuatl and Spanish in Contact
2016–2017
Under the auspices of the project Europe and America in Contact: a Multidisciplinary Study of Cross-cultural Transfer in the New World Across Time, my colleagues and I investigated the long-term evolution of Nahuatl grammatical structure under the influence of Spanish. I formally incorporated theoretical and methodological insights from variationist linguistics into the study design. With this, we investigated distributions of feature variants in individual idiolects over time, controlling for social and geographic variables. One key contribution of this work is that seemingly minor contact-induced changes (from synchronic perspective), such as borrowing a single preposition, can spawn complete systemic realignment, disrupting word order tendencies and unraveling rigid polysynthetic patterns, as in the Nahuatl case. We also noticed that individuals’ proficiency seemed to condition the types of variants preferred, e.g. by language learners, stable-proficiency speakers, or attriters.
The project was funded by an ERC Starter Grant awarded to Justyna Olko under agreement number 312795.
* * *
Dynamics of Language Contact in Suriname
2009-2014
This project was the basis of my doctoral dissertation. Here is the description from the back cover of the dissertation:
Language lives. And just like other living things, languages come into being, develop over time, and eventually die. Often these developments are motivated by interaction with other languages, known as language contact. This dissertation contains a bundle of articles that report on the various ways that languages effect each other and the factors that condition the linguistic results in the Surinamese context.
Following a chapter summarizing socio-historical developments of Suriname from its beginnings as a plantation colony to a modern multiethnic, multilingual country, the reader will find a case study detailing the various formative processes of language mixture, intertwining, and obfuscation that led to the creation of Kumanti, a ritual language spoken among the Ndyuka.
The three subsequent chapters contain case studies of contact-induced language change among Suriname’s languages. The first explores convergence in the semantics of kinship terms in a sample of Surinamese languages. A similar language sample is employed in an investigation of contact induced developments among the languages’ tense, mood, and aspect systems. The following chapter argues that the syntactic structures associated with Dutch particle verbs has been transferred to Suriname’s creole languages. The last case study addresses questions of language death and linguistic variation among a small group of Maroons, the Coppename Kwinti.
These case studies allow for a number of generalizations to be made about the mechanisms and processes of language contact in Suriname which can hopefully be useful in our further understanding of other complex contact settings and language contact in general.
Key contributions arising from this work are:
- the multiple moving targets model, which states that the directionality of language contact and the areas of grammar affected by language contact are highly fluid, and heavily conditioned by socio-political –“language external”– factors (Muysken: “Borges’ Law”);
- a grammar sketch and proposed classification of a ritual / secret language Kumanti;
- identification of novel, contact-induced features in Surinamese creoles, notably Germanic particle verb constructions, which had never been described in the Surinamese context and are not known to exist in any other creole languages.
Find the dissertation here, or message me about language contact in Suriname.
The project was funded as part of an ERC Advanced Grant to Pieter Muysken for the Traces of Contact: Language contact studies and historical linguistics project under agreement number 230310.
* * *
Misc. Research Activities and Collaboration
- 2021 — I coordinated the FAL — Fieldwork in Anthropology and Linguistics — exploring overlapping methodological approaches and possibilities for synergies between the two disciplines at Uppsala University.
- 2019-2020 — I coordinated UPPLADOC, the Uppsala Language Documentation Group at the Department of Linguistics and Philology, Uppsala University.
- 2015 — I was involved in the Endangered languages. Comprehensive models for research and revitalization project, primarily as a consultant in matters of language contact and editor of publications
- 2015 — I coded typological questionnaires (ca. 200 logically independent morphological and syntactic features) for a handful of languages within the GramBank project.
- 2014–2015 — I was involved with the Cognitive Creolistics project at Aarhus University, first as a contractor responsible to check correctness of coded typological feature values, and later as an employee investigating the relationship of the Songhay language family to pidgin and creole languages.