Abandoned Blog (?)
2020-10-15 21:07. Keywords: data analysis, musings
So, the website is almost two years old, and there's still only one blog post to show for it. As I suspected, I didn't have|make the time to post much. I'm tempted to say "that all changes now", but I know it's probably not the case.
2020 has been an interesting year. While I feel like I've been quite busy, I spent a good part of the year without a formal employment. There's not much news in terms of conference presentations or new publications. But I have taught a few courses in Uppsala and Jena. Teaching these courses has been a really rewarding, albeit time consuming, experience
I suppose the main bit of development to report has to do with the new research direction that I've been working on with Volker Gast in Jena and Margot van den Berg in Utrecht. The common theme in these two cooperations is that we're using speech-to-text to automate spoken-language corpus building. Very briefly, raw spoken data in the form of mp4 is processed using a series of shell and python script, which chunks audio, speech-recognizes chunks, and builds a transcribed and time aligned Elan readable .eaf file.
In one case, we (van den Berg and I) worked on data processed in this way from the Surinamese Parliament — De Nationale Assemblée. We took a descriptive, variationist approach to the data, looking at features that have been described in other publications as distinctive in the Surinamese variety of Dutch. The results of our investigation show that a data heavy approach, such as the one we have taken, will lead to a more nuanced understanding of how particular features and their distribution signal "Surinameseness".
In a more recent rendition, Volker Gast and I have been working on data from the European Parliament. So far, I have mainly been dealing with infrastructural issues. In the Europarl case, video files come with multiple embedded audio tracks; every bit of spoken language is translated simultaneously to all the other EU languages and these translations are embedded to the video file. Currently, the pipe extracts all these audio tracks and builds the Elan readable .eaf file with a transcription for each language track.
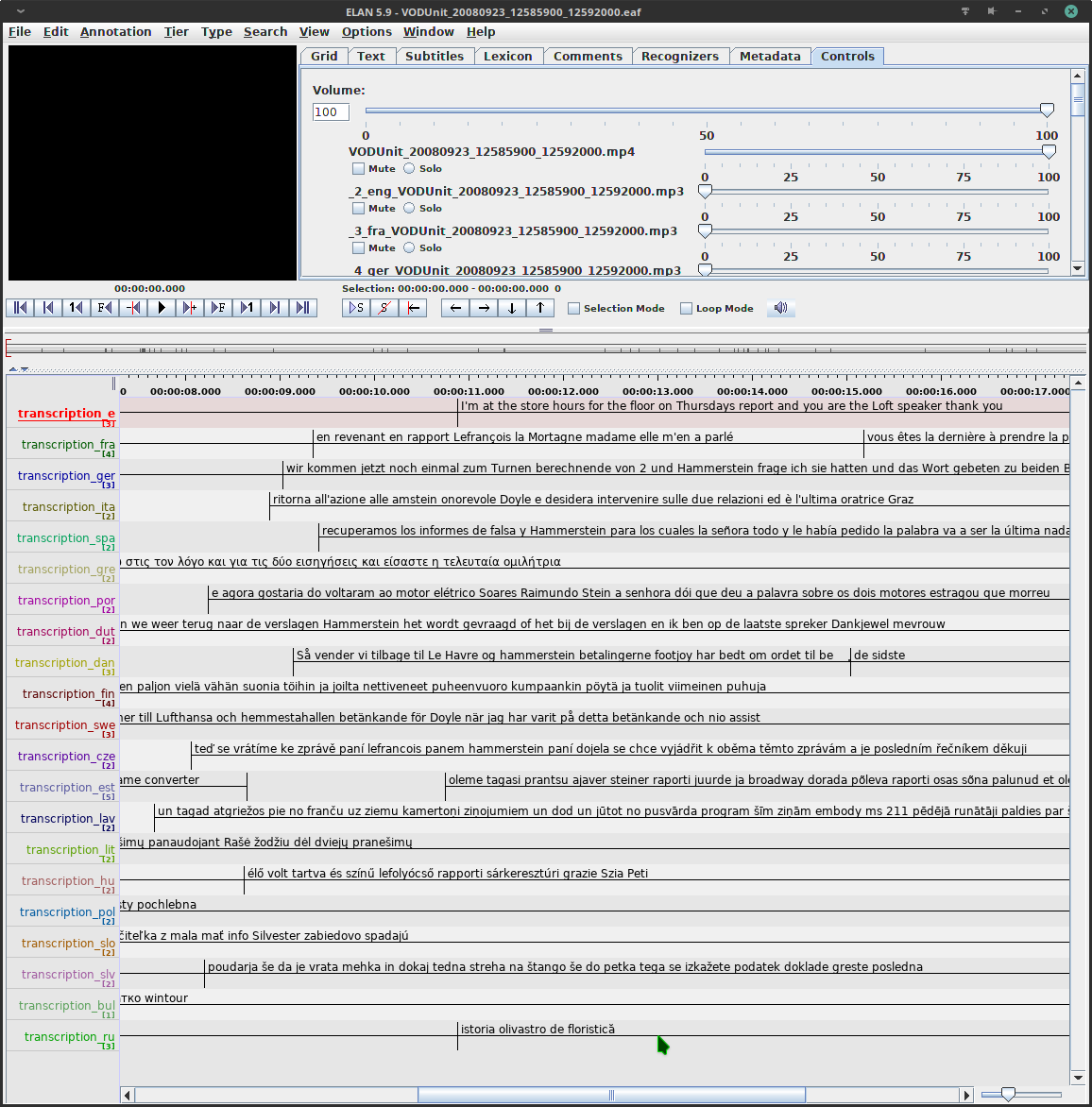
Screenshot of transcriptions resulting from the speech-to-text pipe as seen in Elan
We're still exploring possibilities for exactly how we will proceed with analysis of data, but we see enormous potential to address questions related to the translation studies and the multilingual mind.
Otherwise, I've been spending a lot of time honing technical skills, working with shell scripts and python, a little bit of web development (esp. things that will be useful for research infrastructure), and 'tinkering' a bit with hardware (arduinos and PCs). I received an invitation to Google's 'foobar' challenge, so I spent a few days on that and managed to pass the first three levels — no call from the recruiter yet, but actually I think I might prefer the freedom of research to a corporate job despite the instability.
I don't remember what I had in mind when I referred to my 'technical (r)evolution' in the first blog post, but I have kept up with learning and expanding my own technical capabilities. It's certainly worth the effort it takes to learn new things — generally I think it forces a more structured and more efficient way of working. Personally, I also find it quite satisfying to take such control over my own work flows.
Enter your name | alias and email to comment on this post.